



The Reality About Deepseek Chatgpt In 5 Little Words
페이지 정보
작성자 Lon Cogburn 작성일25-02-08 13:00 조회2회 댓글0건관련링크
본문
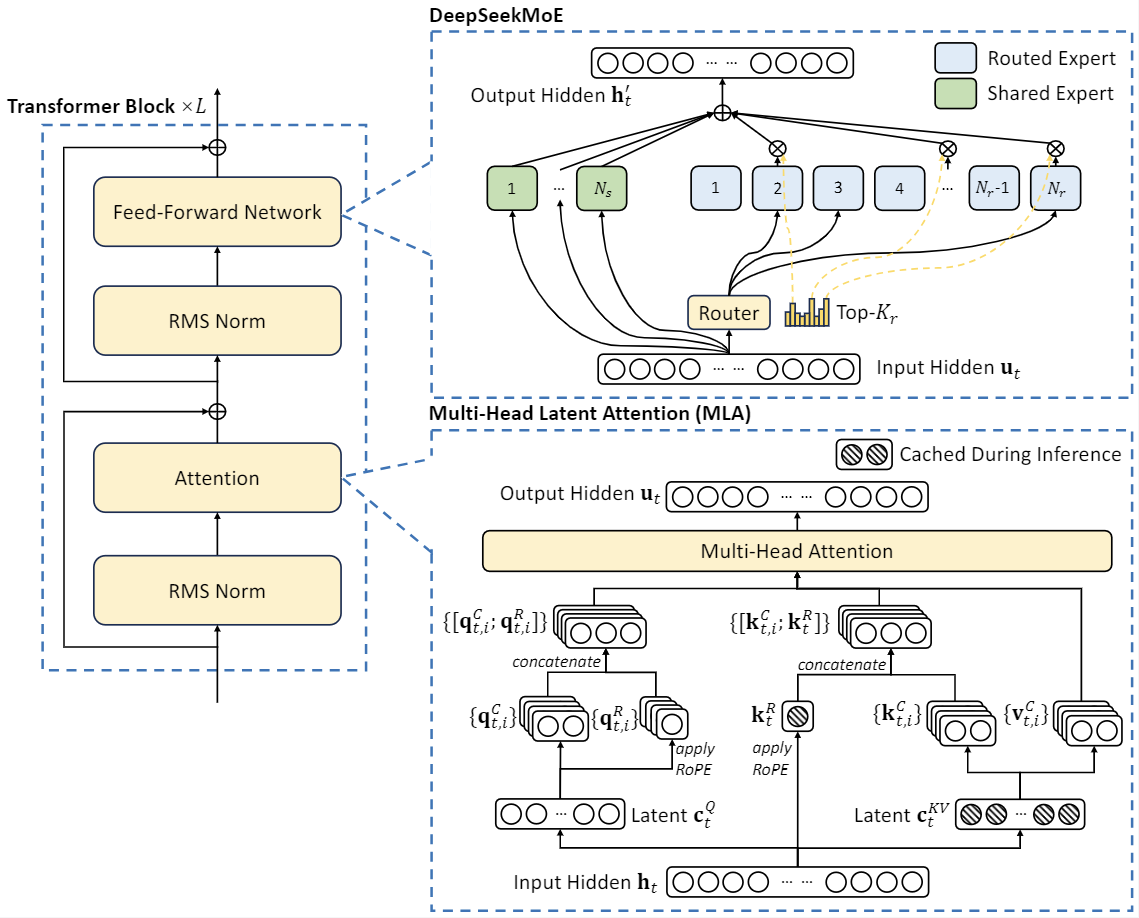 DeepSeek v3 used "reasoning" information created by DeepSeek-R1. The "large language mannequin" (LLM) that powers the app has reasoning capabilities that are comparable to US fashions akin to OpenAI's o1, however reportedly requires a fraction of the fee to practice and run. What has changed between 2022/23 and now which suggests we've at the very least three decent long-CoT reasoning models round? Other LLMs like LLaMa (Meta), Claude (Anthopic), Cohere and Mistral wouldn't have any of that historical knowledge, as a substitute relying solely on publicly accessible information for coaching. Read more: Aviary: training language agents on difficult scientific duties (arXiv). The price of decentralization: An vital caveat to all of this is none of this comes for free - coaching fashions in a distributed method comes with hits to the efficiency with which you light up each GPU throughout training. Is this simply because GPT-four advantages heaps from posttraining whereas DeepSeek evaluated their base model, or is the mannequin still worse in some hard-to-check means? India must amplify its capacity to draw AI expertise with a slew of focused measures to increase its expertise base beyond just a few hundreds to tens of thousands of AI researchers. And so they launch the base model!
DeepSeek v3 used "reasoning" information created by DeepSeek-R1. The "large language mannequin" (LLM) that powers the app has reasoning capabilities that are comparable to US fashions akin to OpenAI's o1, however reportedly requires a fraction of the fee to practice and run. What has changed between 2022/23 and now which suggests we've at the very least three decent long-CoT reasoning models round? Other LLMs like LLaMa (Meta), Claude (Anthopic), Cohere and Mistral wouldn't have any of that historical knowledge, as a substitute relying solely on publicly accessible information for coaching. Read more: Aviary: training language agents on difficult scientific duties (arXiv). The price of decentralization: An vital caveat to all of this is none of this comes for free - coaching fashions in a distributed method comes with hits to the efficiency with which you light up each GPU throughout training. Is this simply because GPT-four advantages heaps from posttraining whereas DeepSeek evaluated their base model, or is the mannequin still worse in some hard-to-check means? India must amplify its capacity to draw AI expertise with a slew of focused measures to increase its expertise base beyond just a few hundreds to tens of thousands of AI researchers. And so they launch the base model!
 It is a decently huge (685 billion parameters) model and apparently outperforms Claude 3.5 Sonnet and GPT-4o on lots of benchmarks. LLaMA 3.1 405B is roughly competitive in benchmarks and apparently used 16384 H100s for the same period of time. They have 2048 H800s (slightly crippled H100s for China). When you do have the 1-day AGI, then that appears prefer it should significantly accelerate your path to the 1-month one. By extrapolation, we will conclude that the next step is that humanity has adverse one god, i.e. is in theological debt and should construct a god to continue. "Chinese firms usually create new manufacturers for oversea merchandise, even one per country, while Western companies desire to make use of unified product names globally." Engineer from Hugging Face Tiezhen Wang said. I get why (they are required to reimburse you for those who get defrauded and occur to use the bank's push payments while being defrauded, in some circumstances) but that is a really foolish consequence. There is way power in being roughly proper very fast, and it incorporates many clever tips which are not instantly apparent but are very highly effective. This specific model doesn't appear to censor politically charged questions, but are there more delicate guardrails that have been constructed into the instrument that are much less simply detected?
It is a decently huge (685 billion parameters) model and apparently outperforms Claude 3.5 Sonnet and GPT-4o on lots of benchmarks. LLaMA 3.1 405B is roughly competitive in benchmarks and apparently used 16384 H100s for the same period of time. They have 2048 H800s (slightly crippled H100s for China). When you do have the 1-day AGI, then that appears prefer it should significantly accelerate your path to the 1-month one. By extrapolation, we will conclude that the next step is that humanity has adverse one god, i.e. is in theological debt and should construct a god to continue. "Chinese firms usually create new manufacturers for oversea merchandise, even one per country, while Western companies desire to make use of unified product names globally." Engineer from Hugging Face Tiezhen Wang said. I get why (they are required to reimburse you for those who get defrauded and occur to use the bank's push payments while being defrauded, in some circumstances) but that is a really foolish consequence. There is way power in being roughly proper very fast, and it incorporates many clever tips which are not instantly apparent but are very highly effective. This specific model doesn't appear to censor politically charged questions, but are there more delicate guardrails that have been constructed into the instrument that are much less simply detected?
They avoid tensor parallelism (interconnect-heavy) by rigorously compacting everything so it matches on fewer GPUs, designed their own optimized pipeline parallelism, wrote their own PTX (roughly, Nvidia GPU meeting) for low-overhead communication to allow them to overlap it better, fix some precision points with FP8 in software program, casually implement a new FP12 format to retailer activations extra compactly and have a bit suggesting hardware design modifications they'd like made. The corporate has mentioned the V3 model was educated on around 2,000 Nvidia H800 chips at an overall value of roughly $5.6 million. ChatGPT maker OpenAI, and was more cost-efficient in its use of expensive Nvidia chips to practice the system on troves of knowledge. But when it comes to where the bulk of the efforts and money are spent, I would presume it remains to be with the everyday person and mundane use instances, and for that to be true until we begin to enter a full takeoff mode towards ASI. However the broad sweep of historical past suggests that export controls, notably on AI models themselves, are a shedding recipe to maintaining our present management status in the sphere, and should even backfire in unpredictable methods.
This opens new uses for these fashions that weren't doable with closed-weight fashions, like OpenAI’s models, attributable to phrases of use or technology prices. Sometimes those stacktraces may be very intimidating, and an important use case of utilizing Code Generation is to help in explaining the problem. If a journalist is using DeepMind (Google), CoPilot (Microsoft) or ChatGPT (OpenAI) for research, they are benefiting from an LLM trained on the complete archive of the Associated Press, as AP has licensed their tech to the companies behind those LLMs. However, OpenAI CEO Sam Altman posted what appeared to be a dig at DeepSeek and different opponents on X Friday. DeepSeek has absurd engineers. The method is straightforward-sounding however filled with pitfalls DeepSeek AI do not mention? DeepSeek V3 was unexpectedly released just lately. It’s extra concise and lacks the depth and context supplied by DeepSeek. As DeepSeek came onto the US scene, curiosity in its know-how skyrocketed. That is where the EY-model "aligned singleton" got here from. The open mannequin ecosystem is clearly healthy. Open Source as a Dominant Strategy: The decision to open supply all models is mentioned, highlighting how this strategy fosters neighborhood engagement and accelerates innovation by collaborative efforts.
In case you loved this informative article and you wish to receive more info regarding ديب سيك شات please visit our internet site.
댓글목록
등록된 댓글이 없습니다.



