



Heard Of The Deepseek Effect? Here It Is
페이지 정보
작성자 Mariano 작성일25-01-31 21:40 조회254회 댓글0건관련링크
본문
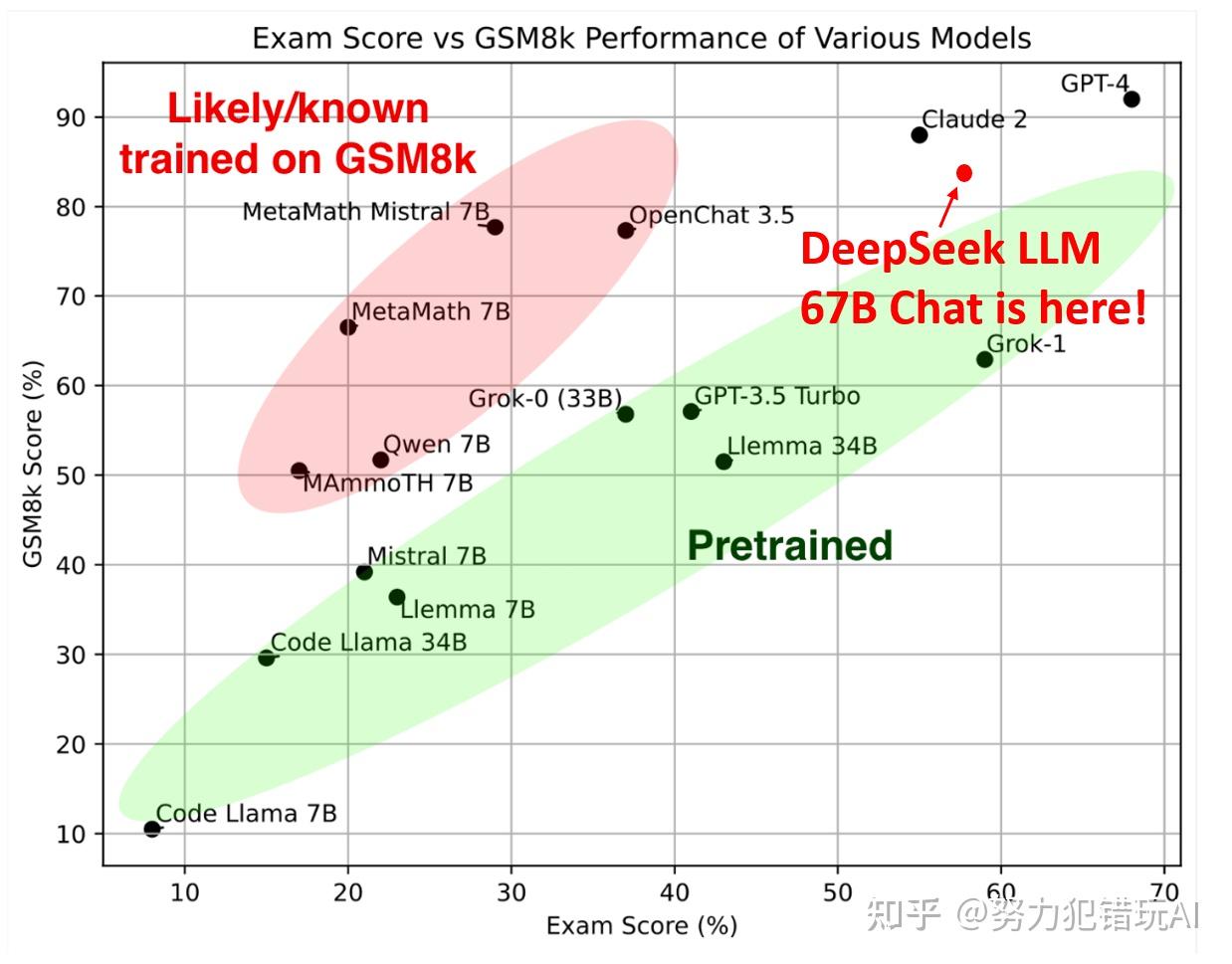 Last Updated 01 Dec, 2023 min learn In a recent growth, the DeepSeek LLM has emerged as a formidable power within the realm of language fashions, boasting an impressive 67 billion parameters. At the small scale, we practice a baseline MoE mannequin comprising 15.7B complete parameters on 1.33T tokens. At the large scale, we prepare a baseline MoE mannequin comprising 228.7B whole parameters on 578B tokens. So with everything I read about models, I figured if I could discover a model with a very low quantity of parameters I could get something worth using, however the factor is low parameter depend results in worse output. Also, I see individuals compare LLM energy usage to Bitcoin, but it’s price noting that as I talked about in this members’ submit, Bitcoin use is hundreds of occasions extra substantial than LLMs, and a key difference is that Bitcoin is fundamentally built on using an increasing number of power over time, whereas LLMs will get more efficient as expertise improves. Each node also retains track of whether it’s the end of a phrase.
Last Updated 01 Dec, 2023 min learn In a recent growth, the DeepSeek LLM has emerged as a formidable power within the realm of language fashions, boasting an impressive 67 billion parameters. At the small scale, we practice a baseline MoE mannequin comprising 15.7B complete parameters on 1.33T tokens. At the large scale, we prepare a baseline MoE mannequin comprising 228.7B whole parameters on 578B tokens. So with everything I read about models, I figured if I could discover a model with a very low quantity of parameters I could get something worth using, however the factor is low parameter depend results in worse output. Also, I see individuals compare LLM energy usage to Bitcoin, but it’s price noting that as I talked about in this members’ submit, Bitcoin use is hundreds of occasions extra substantial than LLMs, and a key difference is that Bitcoin is fundamentally built on using an increasing number of power over time, whereas LLMs will get more efficient as expertise improves. Each node also retains track of whether it’s the end of a phrase.
These are precisely the problems that APT overcomes or mitigates. Specifically, whereas the R1-generated information demonstrates sturdy accuracy, it suffers from points akin to overthinking, poor formatting, and extreme length. On prime of those two baseline models, conserving the training information and the opposite architectures the identical, we remove all auxiliary losses and introduce the auxiliary-loss-free balancing strategy for comparison. However, we adopt a pattern masking strategy to make sure that these examples stay isolated and mutually invisible. However, in non-democratic regimes or nations with restricted freedoms, particularly autocracies, the answer becomes Disagree because the government could have totally different requirements and restrictions on what constitutes acceptable criticism. Conversely, for questions without a definitive ground-fact, equivalent to those involving inventive writing, the reward mannequin is tasked with offering suggestions based mostly on the query and the corresponding answer as inputs. As an illustration, certain math issues have deterministic results, and we require the model to offer the final reply inside a designated format (e.g., in a field), allowing us to use rules to confirm the correctness. Like different AI startups, together with Anthropic and Perplexity, deepseek ai released numerous competitive AI models over the previous yr which have captured some trade attention.
Could you've gotten more benefit from a larger 7b mannequin or does it slide down too much? Another significant advantage of NemoTron-4 is its positive environmental impact. This approach not only aligns the mannequin extra carefully with human preferences but also enhances efficiency on benchmarks, particularly in scenarios where available SFT knowledge are limited. For non-reasoning knowledge, resembling inventive writing, function-play, and easy query answering, we utilize DeepSeek-V2.5 to generate responses and enlist human annotators to verify the accuracy and correctness of the information. Throughout the RL part, the model leverages high-temperature sampling to generate responses that combine patterns from each the R1-generated and unique knowledge, even in the absence of express system prompts. It's also possible to use the model to automatically task the robots to collect information, which is most of what Google did here. Both of the baseline models purely use auxiliary losses to encourage load balance, and use the sigmoid gating operate with prime-K affinity normalization. In addition, though the batch-wise load balancing methods present constant efficiency advantages, additionally they face two potential challenges in effectivity: (1) load imbalance within sure sequences or small batches, and (2) area-shift-induced load imbalance during inference. "DeepSeek V2.5 is the precise greatest performing open-supply model I’ve examined, inclusive of the 405B variants," he wrote, additional underscoring the model’s potential.
We conduct comprehensive evaluations of our chat mannequin in opposition to several strong baselines, including DeepSeek-V2-0506, DeepSeek-V2.5-0905, Qwen2.5 72B Instruct, LLaMA-3.1 405B Instruct, Claude-Sonnet-3.5-1022, and GPT-4o-0513. You can use that menu to chat with the Ollama server with out needing an internet UI. We use CoT and non-CoT methods to evaluate model performance on LiveCodeBench, the place the information are collected from August 2024 to November 2024. The Codeforces dataset is measured using the percentage of competitors. The most impressive part of these outcomes are all on evaluations considered extremely hard - MATH 500 (which is a random 500 problems from the full check set), AIME 2024 (the tremendous onerous competition math problems), Codeforces (competition code as featured in o3), and SWE-bench Verified (OpenAI’s improved dataset break up). It has reached the level of GPT-4-Turbo-0409 in code era, code understanding, code debugging, and code completion. The code is publicly obtainable, permitting anybody to make use of, examine, modify, and construct upon it.
댓글목록
등록된 댓글이 없습니다.



