



I Didn't Know That!: Top Seven Deepseek Chatgpt of the decade
페이지 정보
작성자 Arletha Wilkers… 작성일25-03-02 16:57 조회3회 댓글0건관련링크
본문
For questions with free-form floor-fact solutions, we rely on the reward mannequin to determine whether or not the response matches the expected floor-reality. To validate this, we file and analyze the knowledgeable load of a 16B auxiliary-loss-based baseline and a 16B auxiliary-loss-free model on totally different domains in the Pile check set. The first challenge is of course addressed by our training framework that makes use of large-scale skilled parallelism and information parallelism, which ensures a big dimension of each micro-batch. For reasoning-associated datasets, together with these focused on mathematics, code competition issues, and logic puzzles, we generate the information by leveraging an internal DeepSeek-R1 mannequin. Clearly, code upkeep will not be a ChatGPT core strength. The bug launched by OpenAI resulted in ChatGPT users being proven chat data belonging to others. Both DeepSeek and ChatGPT are pushing the boundaries of artificial intelligence, with potential to reshape industries and redefine human-pc interplay. The DeepSeek Coder helps developers create efficient codes while performing debugging operations. Built to assist developers with real-time code generation, debugging, and documentation, DeepSeek Coder gives a strong alternative to ChatGPT’s coding capabilities. They mentioned that GPT-four could also learn, analyze or generate up to 25,000 words of textual content, and write code in all major programming languages.
 One person apparently made GPT-four create a working version of Pong in just sixty seconds, utilizing a mixture of HTML and JavaScript. Is GPT-4 getting worse? To additional investigate the correlation between this flexibility and the benefit in model efficiency, we moreover design and validate a batch-sensible auxiliary loss that encourages load stability on each coaching batch instead of on each sequence. This flexibility allows consultants to better specialize in several domains. Design method: DeepSeek’s MoE design allows process-particular processing, doubtlessly improving performance in specialised areas. From the table, we are able to observe that the auxiliary-loss-free strategy persistently achieves higher mannequin performance on a lot of the evaluation benchmarks. In response to benchmark tests, DeepSeek R1 achieves 90% accuracy in mathematical problem-fixing, surpassing ChatGPT-4o’s 83% accuracy in superior STEM-associated benchmarks. The French data protection authority, the CNIL, informed the french media BFMTV that they will "analyse" the functioning of DeepSeek and can question the company. 1) Compared with DeepSeek-V2-Base, as a result of improvements in our model structure, the size-up of the mannequin measurement and training tokens, and the enhancement of data quality, DeepSeek-V3-Base achieves significantly higher performance as expected.
One person apparently made GPT-four create a working version of Pong in just sixty seconds, utilizing a mixture of HTML and JavaScript. Is GPT-4 getting worse? To additional investigate the correlation between this flexibility and the benefit in model efficiency, we moreover design and validate a batch-sensible auxiliary loss that encourages load stability on each coaching batch instead of on each sequence. This flexibility allows consultants to better specialize in several domains. Design method: DeepSeek’s MoE design allows process-particular processing, doubtlessly improving performance in specialised areas. From the table, we are able to observe that the auxiliary-loss-free strategy persistently achieves higher mannequin performance on a lot of the evaluation benchmarks. In response to benchmark tests, DeepSeek R1 achieves 90% accuracy in mathematical problem-fixing, surpassing ChatGPT-4o’s 83% accuracy in superior STEM-associated benchmarks. The French data protection authority, the CNIL, informed the french media BFMTV that they will "analyse" the functioning of DeepSeek and can question the company. 1) Compared with DeepSeek-V2-Base, as a result of improvements in our model structure, the size-up of the mannequin measurement and training tokens, and the enhancement of data quality, DeepSeek-V3-Base achieves significantly higher performance as expected.
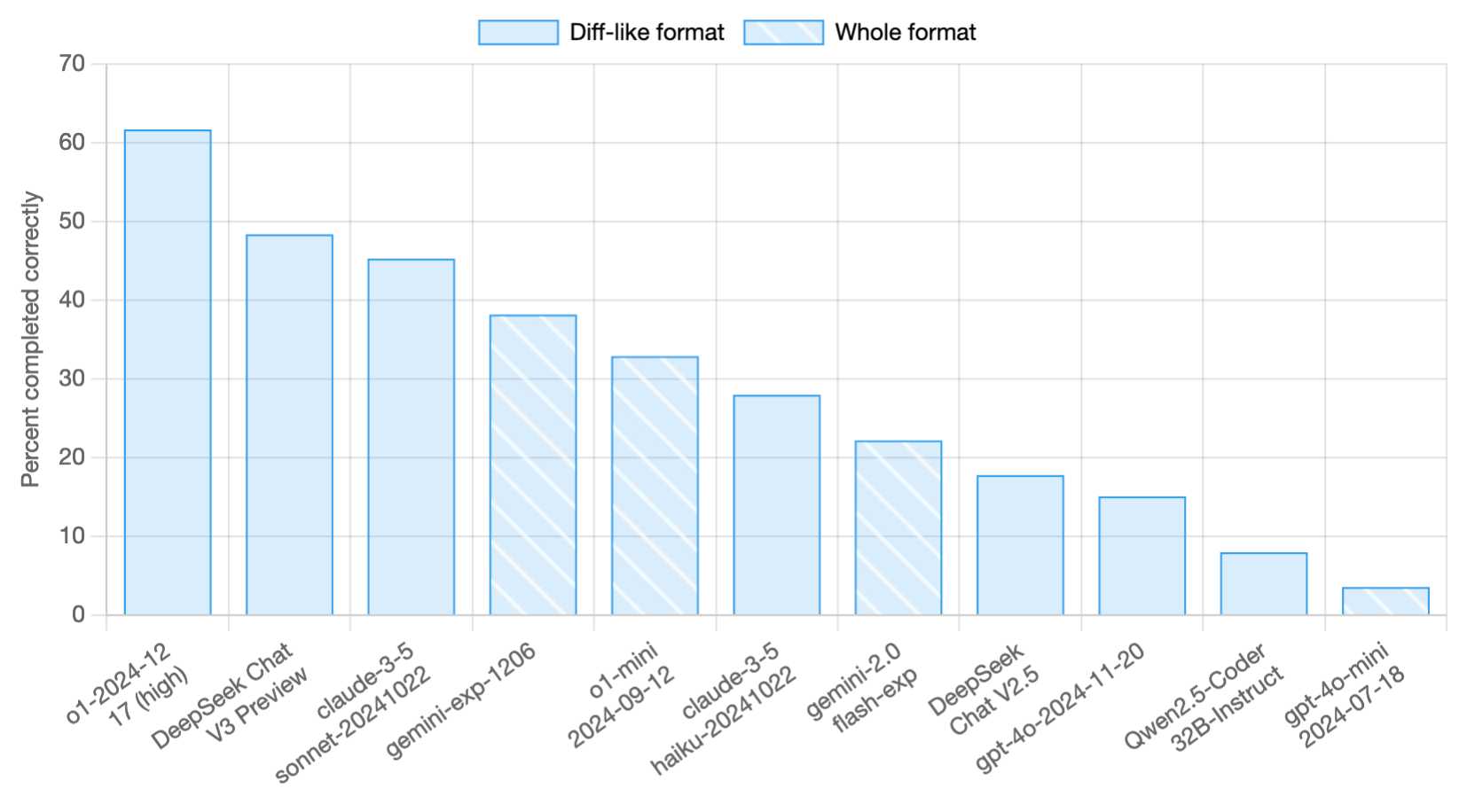 It's value noting that this new mannequin delivers nearly the identical efficiency as OpenAi's a lot-praised o1 mannequin and can also be open supply. The answer there's, you realize, no. The practical answer is no. Over time the PRC will - they've very smart individuals, excellent engineers; lots of them went to the same universities that our prime engineers went to, and they’re going to work around, develop new methods and new strategies and new technologies. Note that during inference, we instantly discard the MTP module, so the inference costs of the compared models are precisely the same. Businesses want to research API costs when they need to include these AI fashions inside their purposes. Want more of the latest from the Star? Compared with the sequence-smart auxiliary loss, batch-sensible balancing imposes a more flexible constraint, because it does not implement in-domain balance on each sequence. The key distinction between auxiliary-loss-Free DeepSeek Chat balancing and sequence-wise auxiliary loss lies in their balancing scope: batch-sensible versus sequence-wise. In Table 5, we show the ablation results for the auxiliary-loss-free balancing strategy. In Table 4, we show the ablation outcomes for the MTP strategy. For mathematical assessments, AIME and CNMO 2024 are evaluated with a temperature of 0.7, and the results are averaged over sixteen runs, while MATH-500 employs greedy decoding.
It's value noting that this new mannequin delivers nearly the identical efficiency as OpenAi's a lot-praised o1 mannequin and can also be open supply. The answer there's, you realize, no. The practical answer is no. Over time the PRC will - they've very smart individuals, excellent engineers; lots of them went to the same universities that our prime engineers went to, and they’re going to work around, develop new methods and new strategies and new technologies. Note that during inference, we instantly discard the MTP module, so the inference costs of the compared models are precisely the same. Businesses want to research API costs when they need to include these AI fashions inside their purposes. Want more of the latest from the Star? Compared with the sequence-smart auxiliary loss, batch-sensible balancing imposes a more flexible constraint, because it does not implement in-domain balance on each sequence. The key distinction between auxiliary-loss-Free DeepSeek Chat balancing and sequence-wise auxiliary loss lies in their balancing scope: batch-sensible versus sequence-wise. In Table 5, we show the ablation results for the auxiliary-loss-free balancing strategy. In Table 4, we show the ablation outcomes for the MTP strategy. For mathematical assessments, AIME and CNMO 2024 are evaluated with a temperature of 0.7, and the results are averaged over sixteen runs, while MATH-500 employs greedy decoding.
Under this configuration, DeepSeek-V3 comprises 671B whole parameters, of which 37B are activated for each token. At the big scale, we practice a baseline MoE mannequin comprising 228.7B total parameters on 578B tokens. POSTSUPERSCRIPT to 64. We substitute all FFNs aside from the primary three layers with MoE layers. POSTSUPERSCRIPT in 4.3T tokens, following a cosine decay curve. POSTSUPERSCRIPT throughout the first 2K steps. 0.3 for the first 10T tokens, and to 0.1 for the remaining 4.8T tokens. The primary tier, with which open commerce in applied sciences is allowed, contains America and 18 industrialized allies. Llama, the AI mannequin released by Meta in 2017, is also open source. As of 2017, fewer than 30 Chinese Universities produce AI-targeted experts and analysis merchandise. DeepSeek, a Chinese AI chatbot reportedly made at a fraction of the cost of its rivals, launched last week however has already grow to be essentially the most downloaded free app within the US. DeepSeek. Check it out on Apple Podcasts, Spotify, or your favourite podcast app. Deepseek free is exploring what intelligence means, he stated.
If you loved this post and you would like to obtain extra data concerning DeepSeek Chat kindly pay a visit to our web page.
댓글목록
등록된 댓글이 없습니다.



